Secure Scuttlebutt Go Database Benchmark
This is a slight follow up to "bbolt on iOS". In that post I wrote about changing the database system used by scuttlego, a new Secure Scuttlebutt implementation used by the Planetary client.
At some point before that time I did some benchmarks on three database systems: Margaret which was used by the previous implementation, bbolt which I've used previously and BadgerDB which I heard about. Those benchmarks weren't well executed at the time and I didn't publish them but I came back to them now and improved them figuring that they may be useful for someone.
The benchmarks were mostly performed to get a better idea of the performance of those databases for the development of the Planetary client which runs on iPhones. Therefore there will be some comments in the article which specifically reference running on mobile devices.
If you want to follow the soure code for the benchmarks while reading this article it is available here.
Environment
goos: linux
goarch: amd64
cpu: AMD Ryzen 7 3700X 8-Core Processor
Versions
The tests were performed with Go 1.20.1, Margaret v0.4.3, bbolt v1.3.7 and BadgerDB v4.0.1.
Storage speed
Benchmarks were peformed on two storage mediums: SSD (a faster medium) and HDD (much slower in comparison). Those mediums were respectively labeled "fast storage" and "slow storage" in benchmark results. I specifically decided to take I/O speed into account as it sometimes very heavily impacts the performance of some databases. For context I/O is fast on iPhones and more similar to "fast storage".
See function getStorageSystems in file bench_test.go.
Data format
I initially experimented with two data formats:
- cryptographically random bytes
- data which more closely resembles SSB messages
I eventually settled on excluding the random data from the benchmark and only including data that resembles SSB messages as they have several characteristics which are important for this test:
- they should be easily compressible as they are very similar to each other and contain the same JSON keys
- most messages have very similar size around 250 to 300 bytes
See function getDataConstructors in file bench_test.go.
Database systems
Configuration
I mostly did my best to avoid changing the default settings of the selected databases. I did that because at least BadgerDB is highly configurable and with different settings the performance results are quite different depending on a specific use case. It is very difficult to determine if those selected settings are actually correct and they all come with trade offs. Furthermore bbolt and Margaret aren't really customizable and I ended up with 20 various versions of BadgerDB in the benchmark and only one version of bbolt and Margaret. This made the results extremly confusing and hard to read. In the end I realised that what I am actually doing is trying to find BadgerDB configuration that performs the best in those syntetic benchmarks which makes no sense.
Compression
Out of the three databases only BadgerDB supports compression out of the box. It can be set to perform no compression, use ZSTD or Snappy. The former provides better but slower compression and the latter provides worse but faster compression. I ran BadgerDB in all three modes for this benchmark.
I specifically considered compression during those benchmarks while excluding other configuration options as database size is important on mobile devices and these days compression often improves performance as processing power is usually abundant and compression enables faster I/O.
I tried adding compression and decompression steps using the same algorithms to bbolt and Margaret but that proved to be futile. There was a significant performance hit and no real decrease in size as each value was compressed separately. I therefore excluded those attempts from the benchmarks but you can still see this code in the repository. I don't see how compression could be performed on larger blocks of data with those databases without altering their source code.
Transactions
To give everyone a fair chance in case of BadgerDB and bbolt I did my best to select transaction sizes which made them perform the best. This seemed to be 5000 elements.
For context Margaret does not provide any transaction mechanism so you most likely have to run it together with a different database system in a primary-secondary configuration. This may introduce extra overhead.
See function getDatabaseSystems in file bench_test.go.
Performance benchmarks
I included four performance benchmarks in the final results. They were selected to test a wide range of use cases. As always I try to give everyone a fair chance and I did my best to force databases to sync the data to disk before I considered that they finished saving it. This is important given that most of them use mmap to perform writes which is usually not immediately synced to disk giving a false impression about their performance. Moreover while mmaped memory will most likely survive process crashes it will not survive a complete system crash or power outage. Our goal then is to actually persist the data while saving it.
Appending values
The first benchmark titled "append" appends 5000 values batched in the preferred transaction sizes for each system to a feed. This is a very common operation when replicating feeds.
Random reads
The second benchmark titled "read_random" performs 5000 random reads from a log which contains 100000 entries. This is supposed to replicate the situation where we have a lot of cache misses and systems have to load data from disk.
Sequential reads
The third benchmark titled "read_sequential" performs 5000 reads for sequential keys from a log which contains 100000 entries. This is supposed to replicate the situation where the systems may have an opportunity to use their caching mechanisms.
Iteration
The fourth benchmark titled "read_iterate" performs an iteration over 5000 elements of a log which contains 100000 entries. This is supposed to replicate the common situation where we need to stream messages to someone. This benchmark specifically attempts to use the iterators (or cursors in case of bbolt/queries in case of Margaret) implemented by the database systems in the hope that they will give us better performance.
See function getBenchmarks and BenchmarkPerformance in file bench_test.go.
Database size benchmark
As I mentioned the database size was important to me so I also tried to measure the database size after inserting a certain number of elements into it. The benchmark titled "BenchmarkSize" inserts a certain number of elements and specifically tries to find the scenario where the average space occupied by each element is the smallest. This is done because those databases often grow in large increments so I tried to be fair and find the smallest number.
This benchmark is the most unfair for bbolt as bbolt grows its file in large increments. Initially the size of the underlying file is multiplied by two and then once it is at above 1 GiB in size 1 GiB is added to it every time the database runs out of space. I did my best to force bbolt to compact the database and even peformed binary search to find the exact moment just before the file grows but eventually gave up as nobody would do this in a real scenario.
See function BenchmarkSize in file bench_test.go.
Results
The number on the Y axis represents "ns per op" and is a result of performing multiple complex operations. It shouldn't be therefore compared across the graphs and is only meaningful to compare performance within a single graph. This is why below the graphs I decided to replace this number with a relative comparison to the worst-performing system for a given benchmark.
Performance - fast storage
Append
Smaller value indicates better performance.
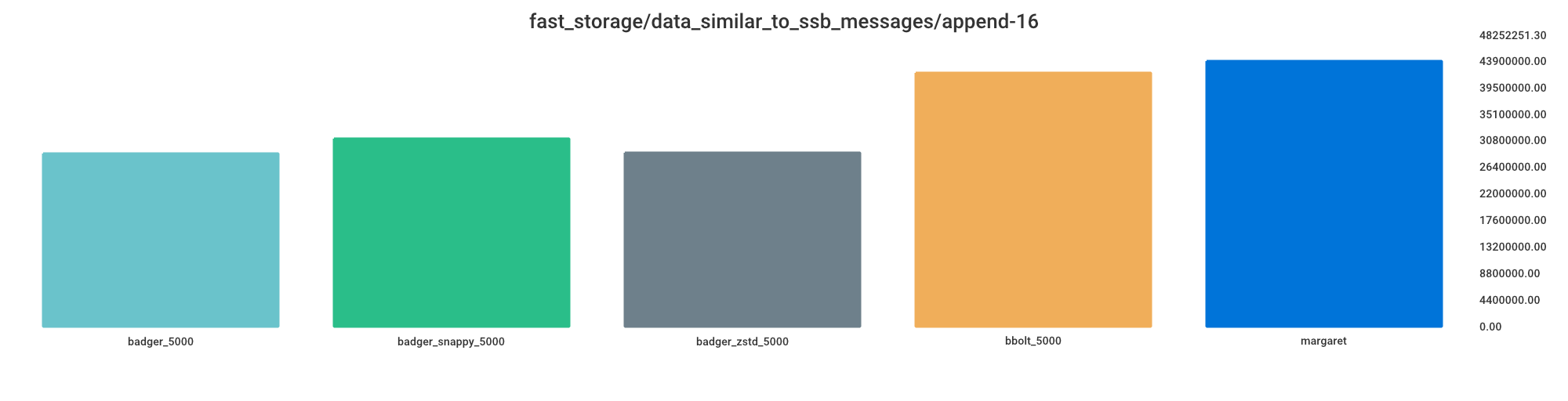
badger_5000 = 65% processing time
badger_zstd_5000 = 66% processing time
badger_snappy_5000 = 71% processing time
bbolt_5000 = 96% processing time
margaret = 100% processing time
Read random
Smaller value indicates better performance.
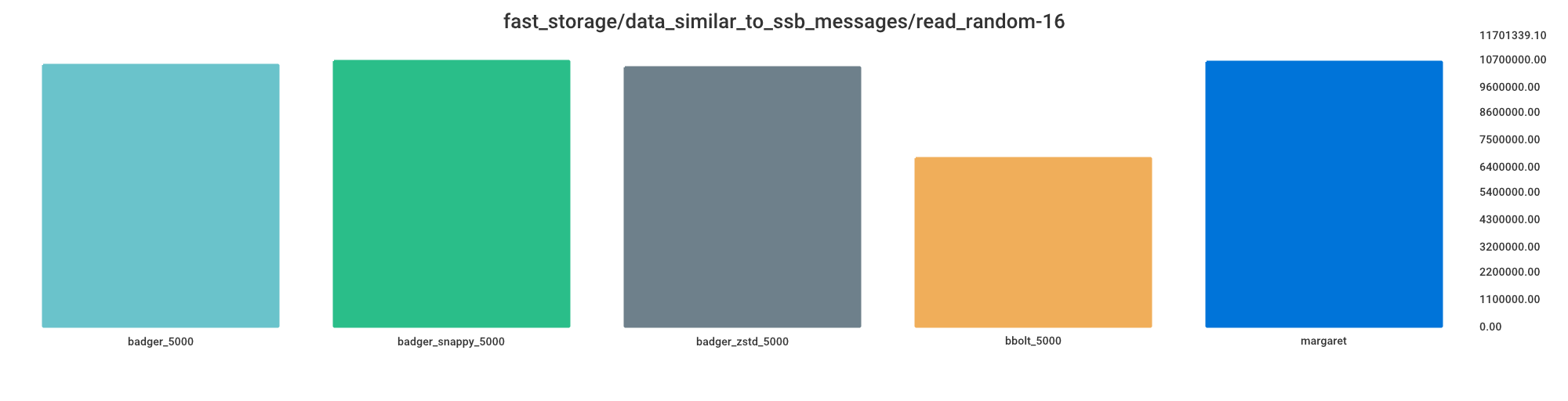
bbolt_5000 = 63% processing time
badger_zstd_5000 = 98% processing time
badger_5000 = 99% processing time
margaret = 100% processing time
badger_snappy_5000 = 100% processing time
Read sequential
Smaller value indicates better performance.
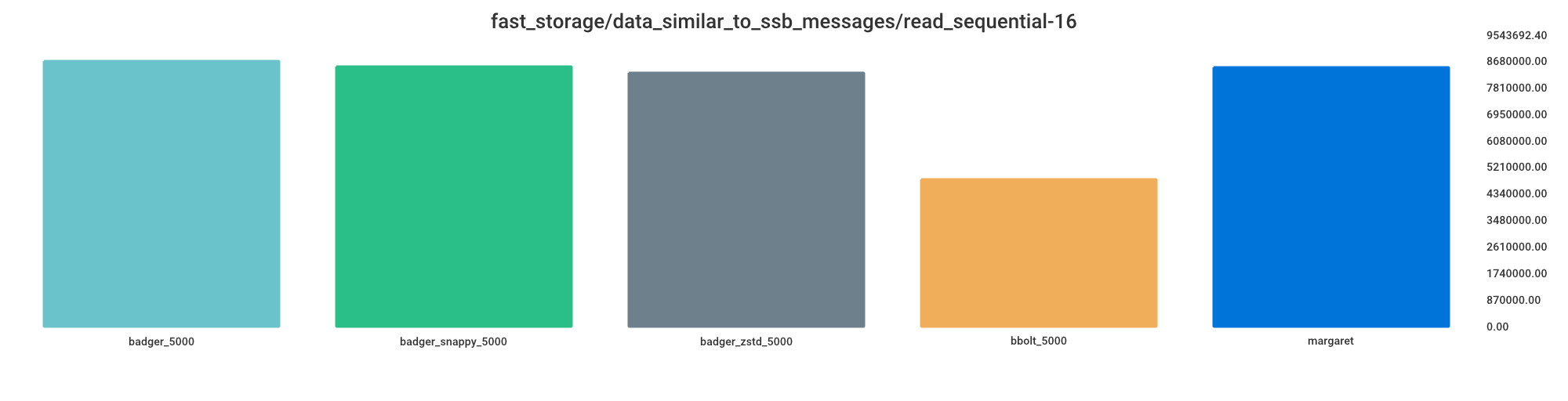
bbolt_5000 = 55% processing time
badger_zstd_5000 = 96% processing time
margaret = 98% processing time
badger_snappy_5000 = 98% processing time
badger_5000 = 100% processing time
Read iterate
Smaller value indicates better performance.
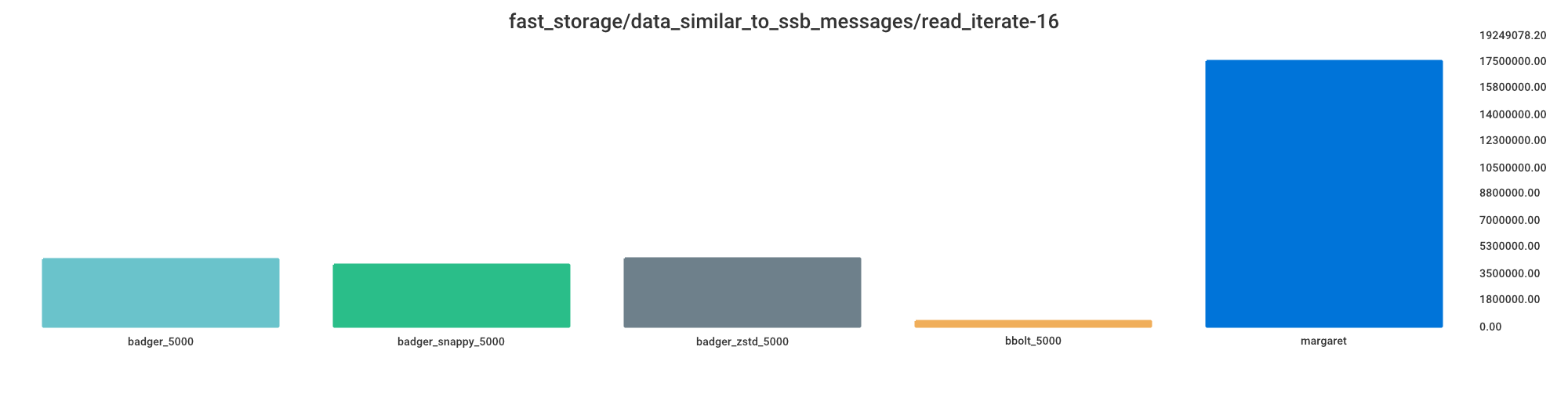
bbolt_5000 = 2% processing time
badger_snappy_5000 = 23% processing time
badger_5000 = 25% processing time
badger_zstd_5000 = 25% processing time
margaret = 100% processing time
Performance - slow storage
Append
Smaller value indicates better performance.
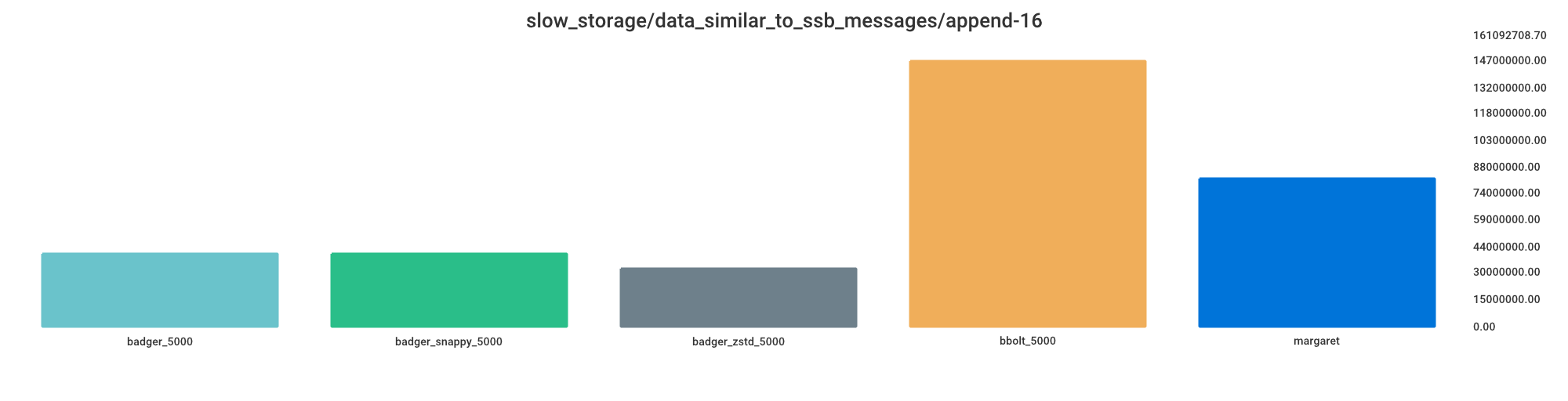
badger_zstd_5000 = 22% processing time
badger_5000 = 27% processing time
badger_snappy_5000 = 27% processing time
margaret = 56% processing time
bbolt_5000 = 100% processing time
Read random
Smaller value indicates better performance.
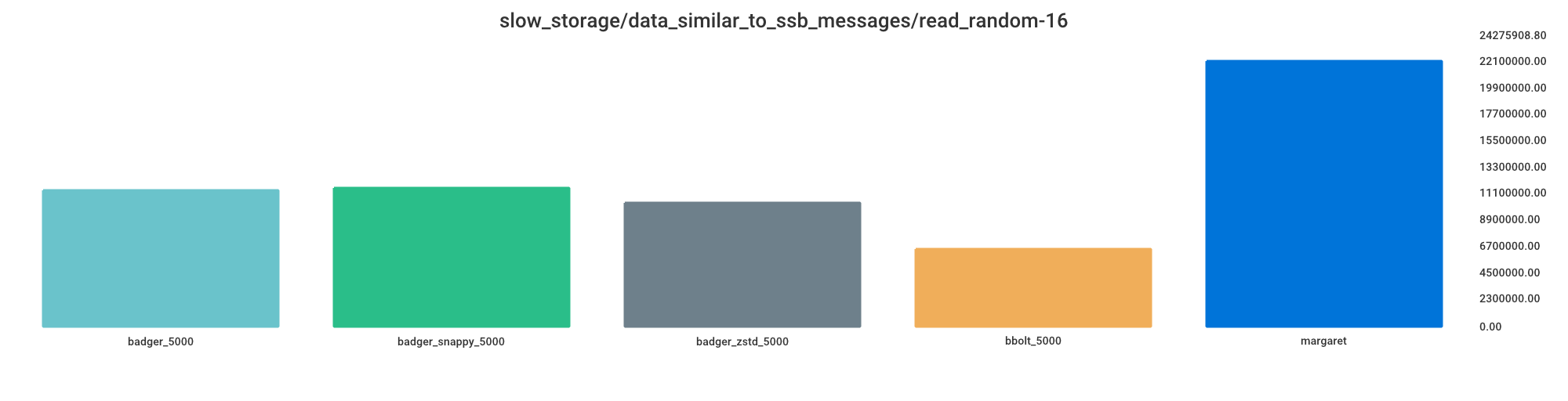
bbolt_5000 = 29% processing time
badger_zstd_5000 = 46% processing time
badger_5000 = 51% processing time
badger_snappy_5000 = 52% processing time
margaret = 100% processing time
Read sequential
Smaller value indicates better performance.
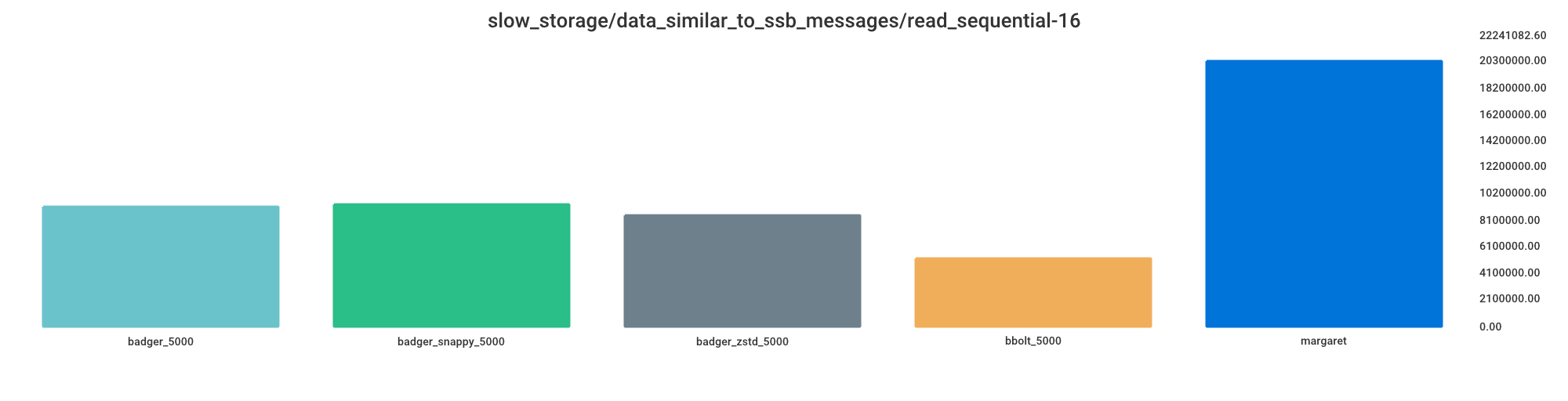
bbolt_5000 = 25% processing time
badger_zstd_5000 = 42% processing time
badger_5000 = 45% processing time
badger_snappy_5000 = 46% processing time
margaret = 100% processing time
Read iterate
Smaller value indicates better performance.
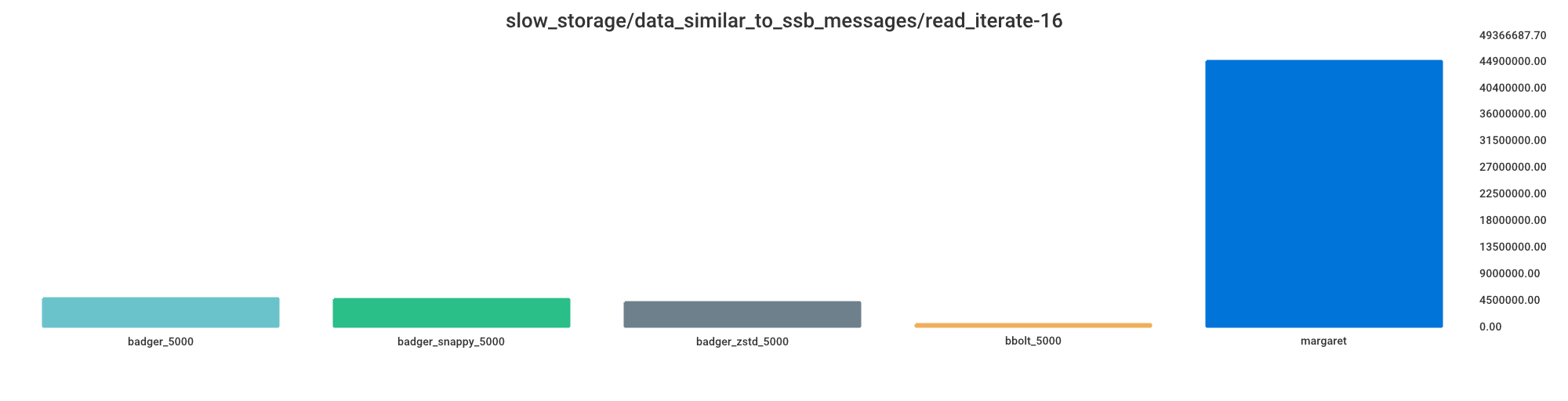
bbolt_5000 = 1% processing time
badger_zstd_5000 = 9% processing time
badger_snappy_5000 = 10% processing time
badger_5000 = 10% processing time
margaret = 100% processing time
Size
Smaller value indicates less storage space used.
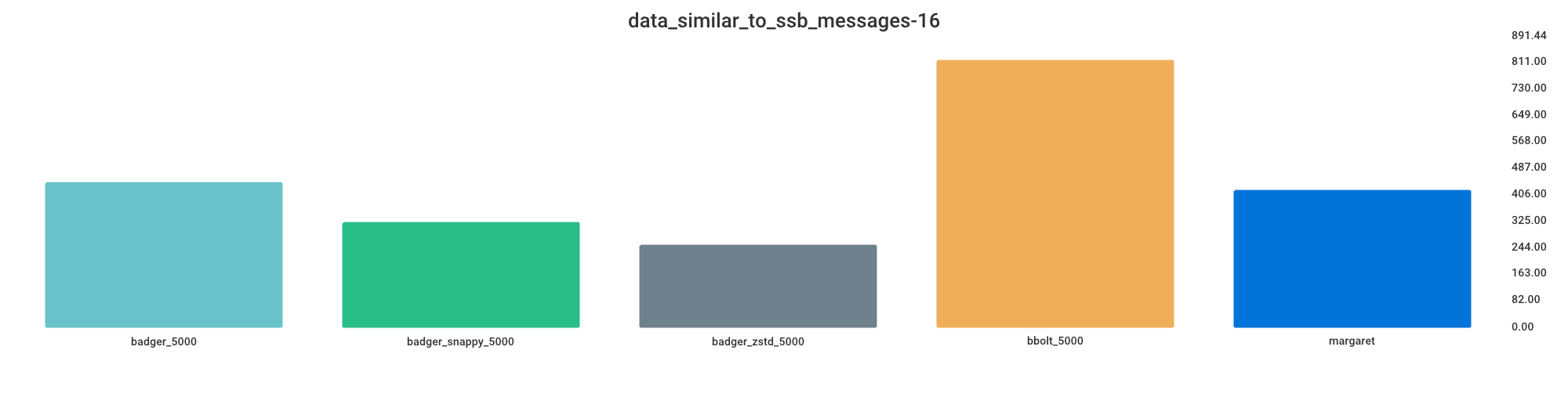
badger_zstd_5000 = 30% storage space
badger_snappy_5000 = 39% storage space
margaret = 51% storage space
badger_5000 = 54% storage space
bbolt_5000 = 100% storage space
Again, please note that I believe bbolt has a disadvantage here as most of that file is probably empty, although I guess this still matters are the user will see this as space as consumed by the app and unusable for anything else.
Conclusions
I think that those results should be treated with a healthy dose of scepticism like any benchmarks. If you can spot any obvious mistakes in the code that impacts the performance of some of those databases please let me know.